- Published on
- • 7 min read
Tool Calling in LLMs: How Models Talk to the Real World
- Authors

- Name
- Shaiju Edakulangara
- @eshaiju
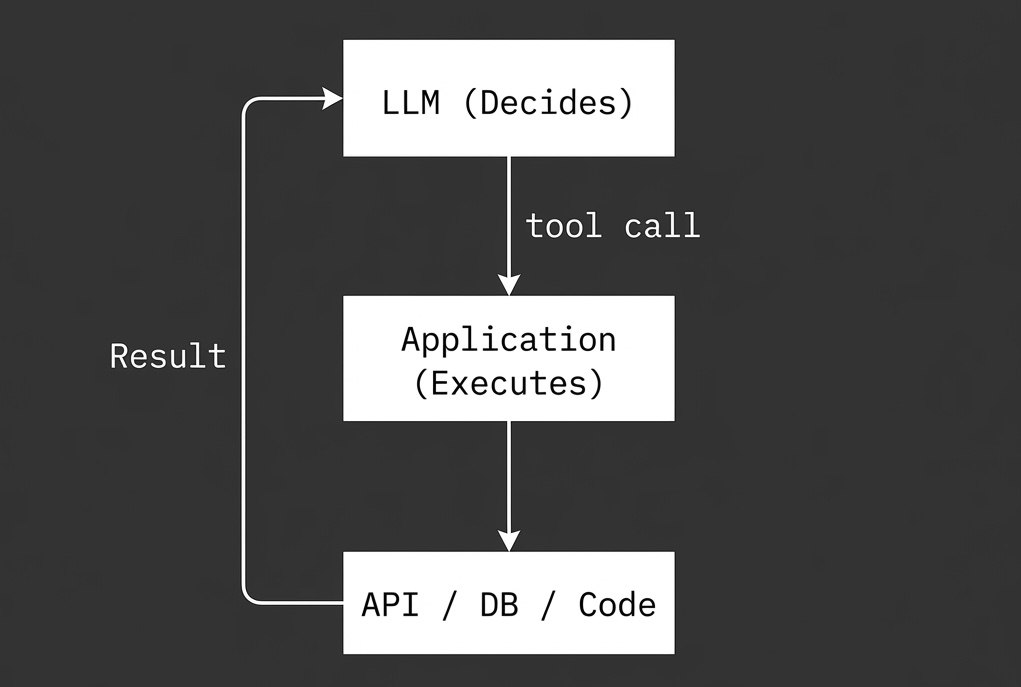
Once you see tool calling this way, the rest of the design makes more sense.
When I first started building with LLMs, I treated them like magic boxes. But I quickly realised: they're great at text, but terrible at doing actual work.
They don’t know your internal docs. They can’t query your database. They definitely can’t send emails or trigger workflows on their own. Yet, in practice, this is exactly what we need them to do.
Tool calling is the architectural bridge that connects the model’s reasoning to your application’s capabilities.
Thinking vs. Doing
So far, this sounds simple. It isn’t.
At its heart, tool calling separates Thinking from Doing.
- The Model decides what to do.
- Your App actually does it.
Asking “What’s the weather?” is thinking. Calling a weather API is doing.
This separation sounds obvious, but many early implementations mix the two—and pay for it later. It's easy to blur this line and end up debugging prompt behaviour instead of system behaviour.
The model never executes code. It only requests that something be done.
Keeping this boundary clear simplifies both reasoning and debugging.
What “Tool Calling” Actually Means
Tool calling is not the model doing anything. It’s the model asking your application to do something.
When the LLM determines it needs external information, it doesn't return a human-readable sentence. Instead, it stops generating text and returns a Tool Call object—or even multiple tool calls at once if it determines it can perform several actions in parallel.
Think of it as the model answering:
“To answer this, I need to call the
document_searchtool withquery = refund policy.”
Under the hood, that response looks like a structured JSON object:
{
"tool_calls": [
{
"id": "call_abc123",
"type": "function",
"function": {
"name": "document_search",
"arguments": "{\"query\": \"refund policy\"}"
}
}
]
}
This is the "intent" phase. The model isn't "doing" the search; it is asking you to do it. Your application parses this JSON, runs the actual search, and provides the results back in the next turn.
Crucially, models can request multiple tool calls in a single response (Parallel Tool Calling) if they identify multiple independent actions that need to be taken to fulfill the request.
The Tool Calling Loop
In practice, tool calling looks like a loop:
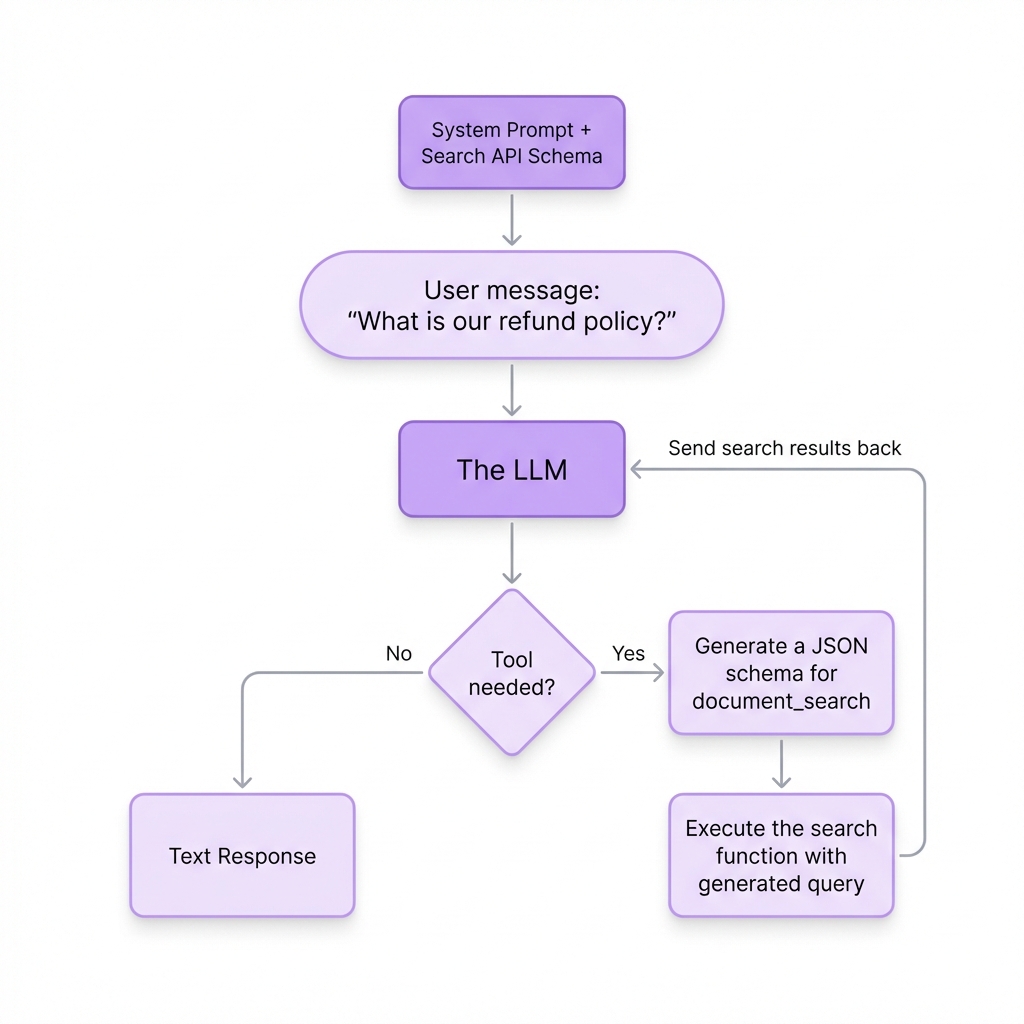
- User asks a question.
- Application sends: Conversation history + Tool definitions.
- Model responds: Either with text or with one or more tool calls.
- Application executes the tool(s).
- Tool result(s) are sent back to the model.
- Model continues reasoning: Based on the results, it may provide a final answer or it may trigger another tool call if the results revealed that further action is needed.
This loop is iterative. A single user request can trigger a "chain" of tool calls, where each step depends on the result of the previous one.
If this loop feels familiar, it’s because it looks a lot like a request–response cycle you already understand.
Tool calling works because it replaces guesswork with a structured protocol. The model must specify the exact tool and the exact parameters required.
If you’ve ever wondered why your model keeps calling the same tool over and over, this is usually why—the parameters it's getting back don't satisfy its next reasoning step.
Implementation: The NodeLLM Way
In NodeLLM, tools are defined as classes with a structured schema. This gives the model clear instructions and gives you full type safety in your application.
import { Tool, z, createLLM } from "@node-llm/core";
// 1. Define the Tools
class DocumentSearch extends Tool {
name = "document_search";
description = "Searches knowledge base for relevant information";
schema = z.object({ query: z.string() });
async handler({ query }) {
const docs = await db.documents.search(query).limit(3);
return docs.map(doc => `${doc.title}: ${doc.content}`).join("\n\n");
}
}
class SlackNotification extends Tool {
name = "send_slack";
description = "Sends a message to a Slack channel";
schema = z.object({ message: z.string(), channel: z.string() });
async handler({ message, channel }) {
await slack.send(channel, message);
return "Notification sent successfully";
}
}
// 2. Usage
const llm = createLLM({ provider: "openai" });
const chat = llm.chat("gpt-4o")
.withTools([DocumentSearch, SlackNotification])
.withInstructions("Search for context. If you find a security issue, notify Slack.");
const response = await chat.ask("What is our security policy?");
NodeLLM handles the heavy lifting—like parallel tool calls and error handling—under the hood. You can find the full API reference in the official documentation.
How the LLM Decides Which Tool to Call
This part is subtle, and small mistakes here lead to confusing behaviour later. It’s not just about the code; it's about how the model "knows" which tool to use. It doesn't have access to your source code; it only has access to the metadata you provide.
When you define a tool in NodeLLM or any other LLM framework, you are essentially writing a small instruction manual for the model:
- The Name: Signals the high-level intent (e.g.,
document_search). - The Description: Provides the "why" and "when".
- The Schema: Defines the "what" (the specific parameters required).
Think of these as semantic prompts. Before every response, the LLM maps the user's request against your tool descriptions.
This is where you can easily trip up. A vague description is a recipe for hallucinations.
| Quality | Description Example | Result |
|---|---|---|
| Bad | description = "Get data" | Model guesses when to use it, or ignores it entirely. |
| Good | description = "Retrieves recent order history including status and delivery date." | Model knows exactly when this tool is the right tool for the job. |
If the request matches the description, the model "invokes" the tool by generating a structured JSON object matching your schema.
This is why descriptions are as important as implementation. If your description is vague, the model will hallucinate calls or ignore the tool entirely. Precise descriptions guide the model’s reasoning environment.
Where Things Get Complicated
Most examples online show a single tool call. Real systems are rarely that simple.
In production, you often need to handle:
- Multiple tool calls in a single turn
- Tool failures and retries
- Timeouts and state management
- Streaming partial results
None of these problems show up in examples. They appear once you start composing features. This orchestration logic lives outside the model, in your runtime.
Tool Calling vs “Agents”
Tool calling is often confused with agents. They are related, but different.
Tool calling is the mechanism. Agents are a pattern built on top of it. An agent is simply a loop where the model reasons, calls tools, receives results, and decides what to do next. You can use tool calling without building agents, but you cannot build agents without tool calling. To see this in action, check out Building Your First AI Agent in Node.js.
Common Failure Modes
Tool calling does not magically remove problems. Some common issues teams run into:
- The model calls tools too often (looping): This happens when the tool's output doesn't give the model what it needs to stop, so it tries again. This can quickly spiral if you don't enforce a
maxStepsor recursion limit in your implementation. - Tool descriptions are too vague: See the table above—this is the #1 cause of "dumb" model behaviour.
- Business logic leaks into prompts: Keep your handlers for logic and your descriptions for intent.
- The model assumes state that no longer exists: Models are stateless; they only know what's in the current window.
This is where things usually go wrong—and it's almost always a design problem, not a model problem.
Closing Thoughts
Tool calling isn’t new or mysterious.
What matters is treating it like architecture instead of a prompt trick. By separating reasoning from execution, you gain better control, easier debugging, and the freedom to evolve your architecture over time.
As LLMs become embedded deeper into real software, this boundary will matter more than any specific model or provider.